
OpenAIのWhisperでは話者の識別ができなかったので次に調べたのはAmazon Transcribeでした。今回はAmazon Transcribeの使い方について解説します。
Amazon Transcribeとは?
Amazon Transcribeはフルマネージド型の自動音声認識サービスです。S3に格納された音声ファイルを指定することで複雑な設定をすることなく音声データから文字起こしをすることができます。文字起こしの結果はS3に格納され、90日間保存されます。
管理コンソールでの動かし方
- 音声ファイルをS3に格納します。
- トランスクリプションジョブからジョブを作成をクリック
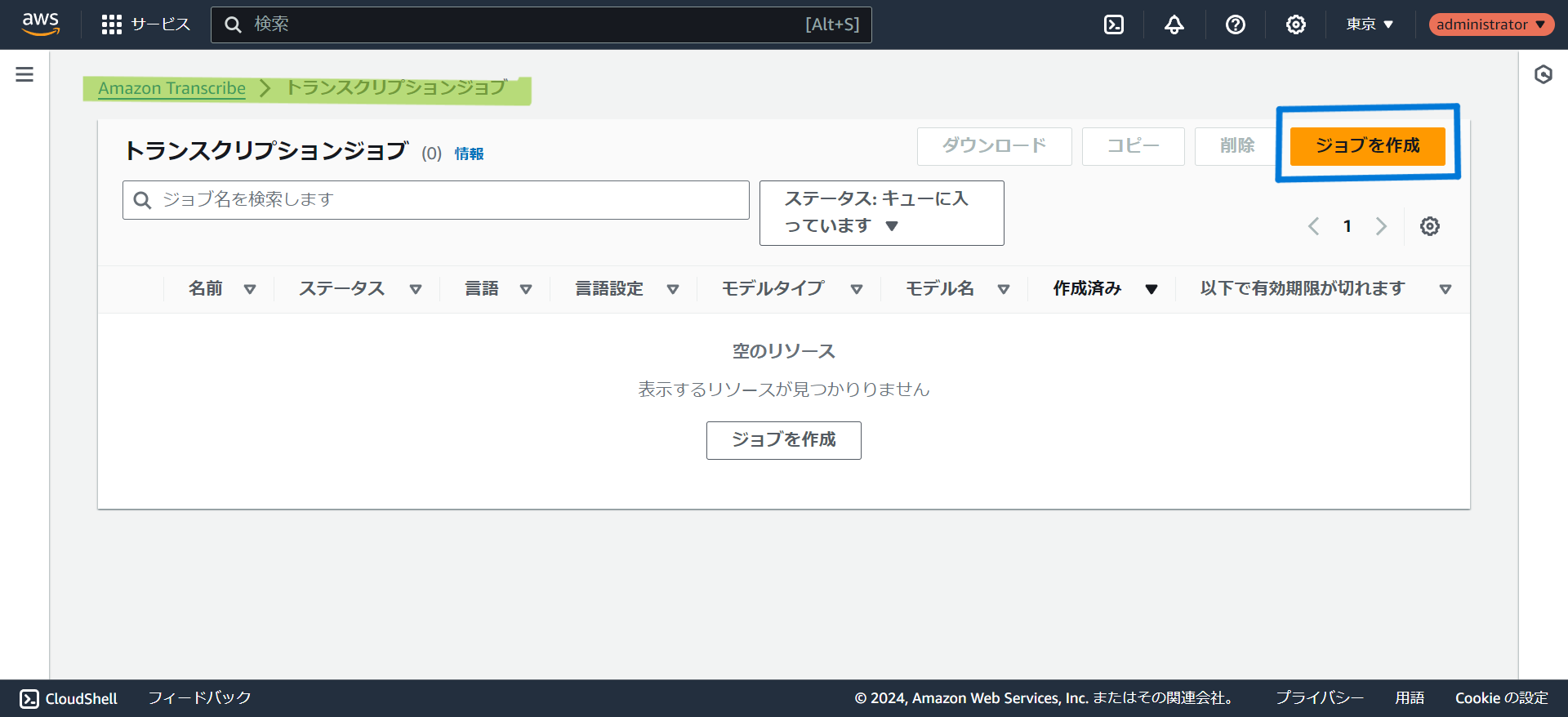
- ジョブ名を入力します。
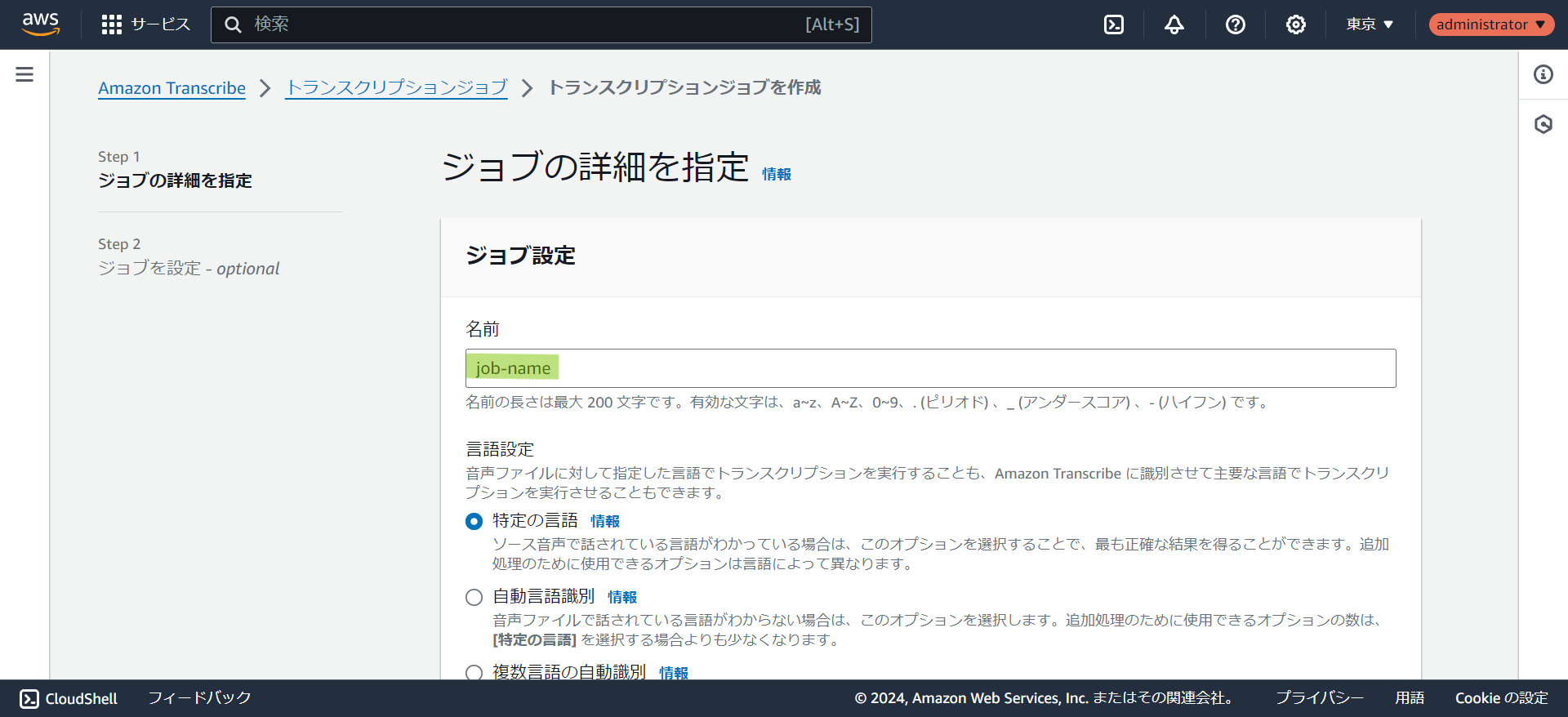
- 特定の言語を選択し、言語で日本語を選択します。
- ①で音声データを格納したS3のURIを入力します。
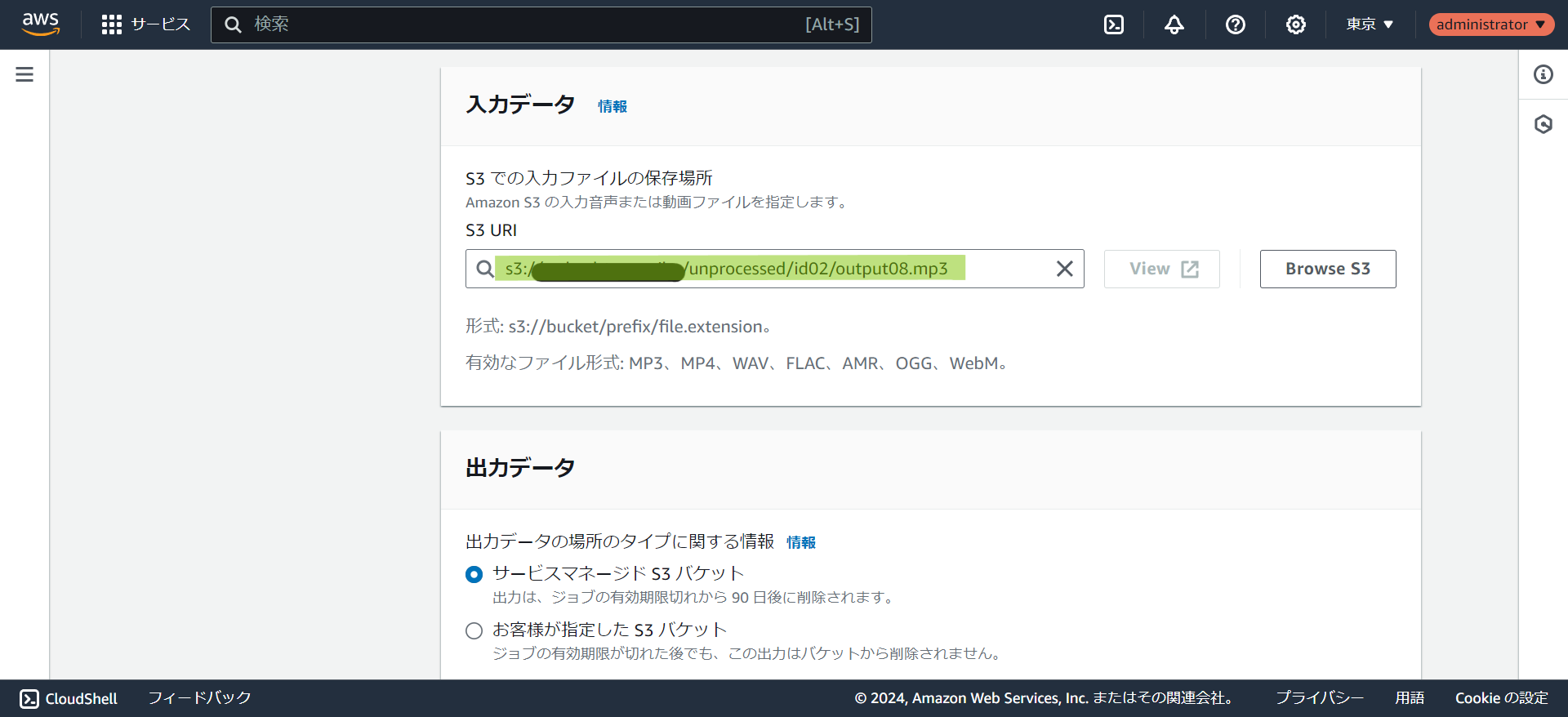
- 出力先のS3バケットを選択します。事前に作成しなくてもマネージドS3バケットを選択して実行可能です。字幕データを作りたい場合は
SRTかVTTにチェックを入れます。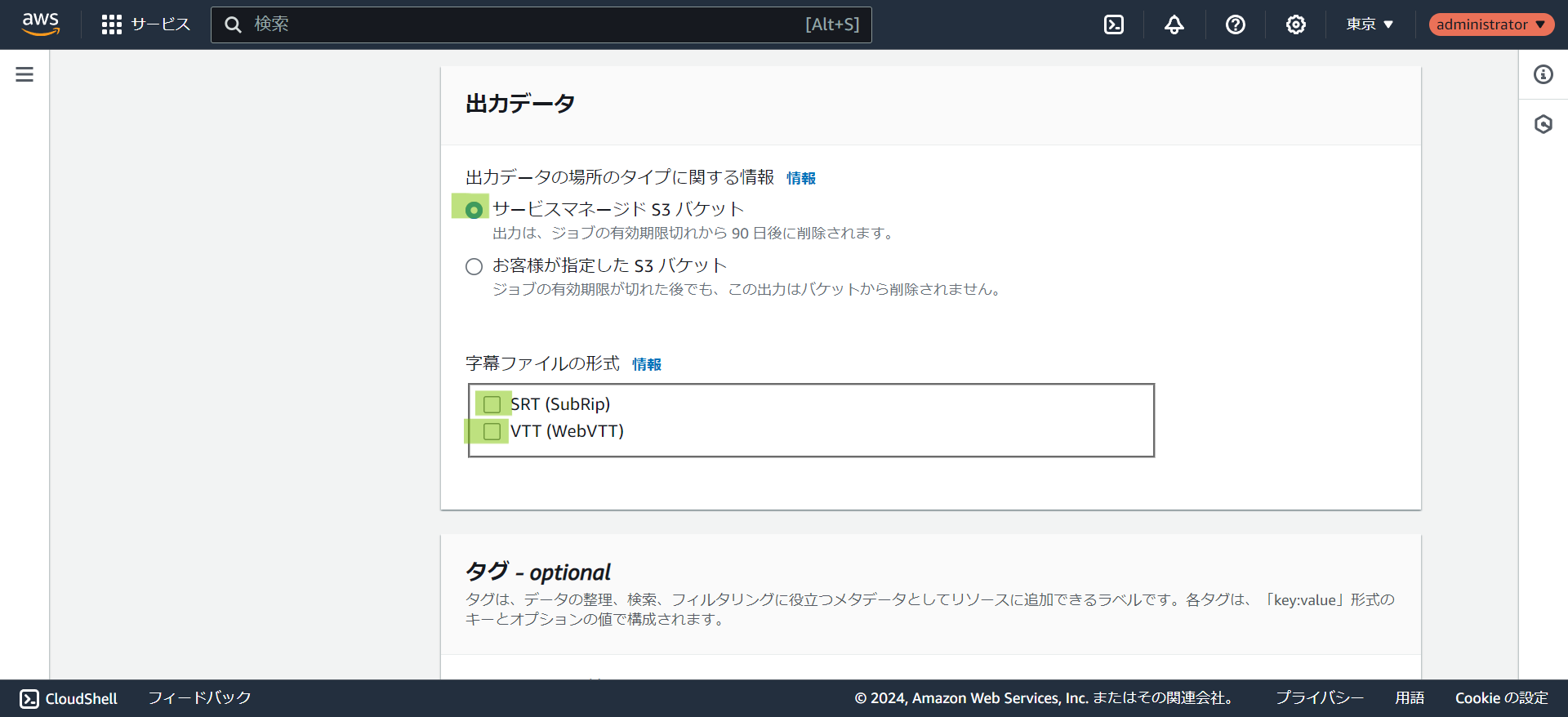
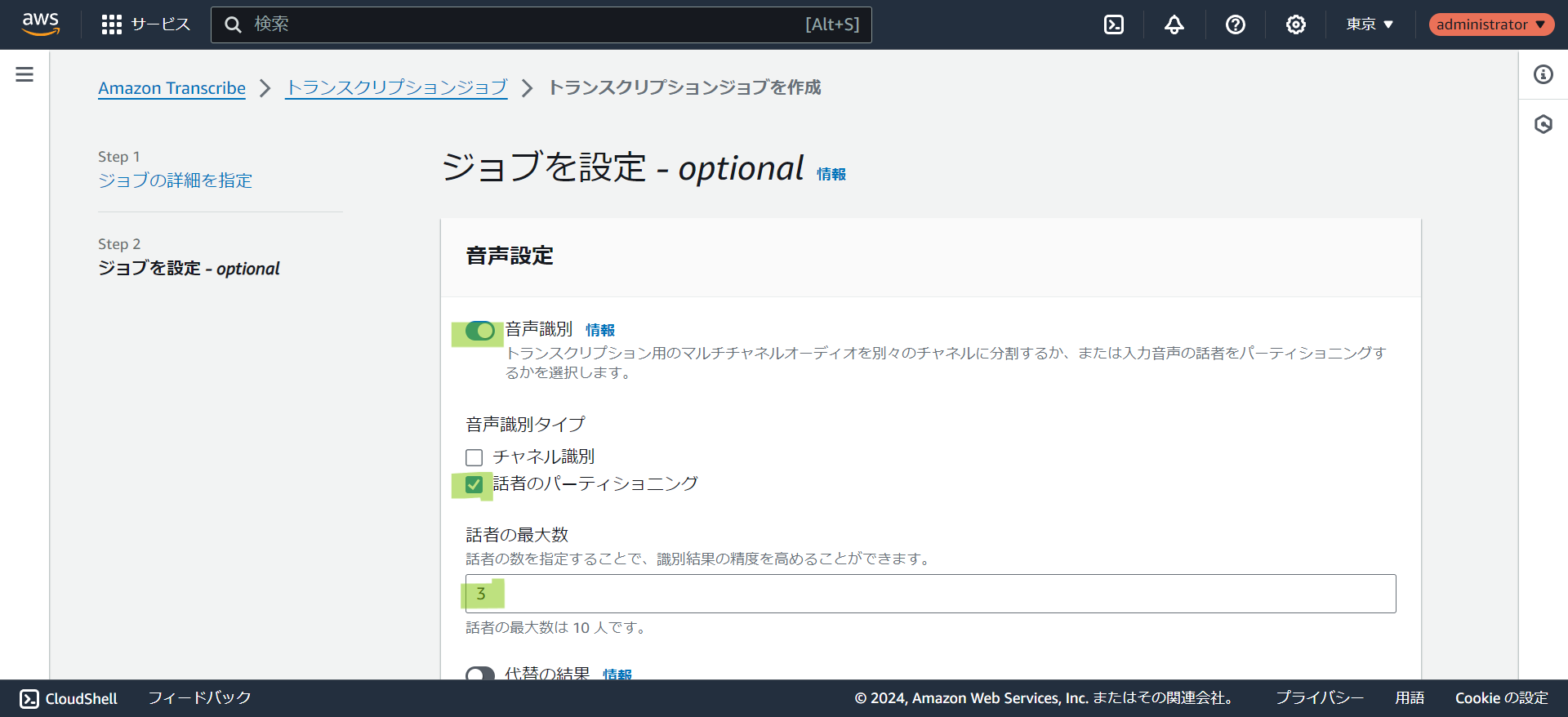
- 音声設定を入力します。
- ジョブを作成をクリックします。
音声識別の設定について
音声識別タイプには2つのチェックボックスがあります。音声データの状況によって選択して下さい。
- チャネル識別:
Web会議などで異なる空間の音声がある場合に選択します。 - 話者のパーティショニング:
複数の話者がいる音声の場合に話者を識別する場合に選択します。選択した場合は追加で話者の最大数を入力します。
結果の確認
- 管理コンソールでステータスが完了になっていれば文字起こしが終わっています。
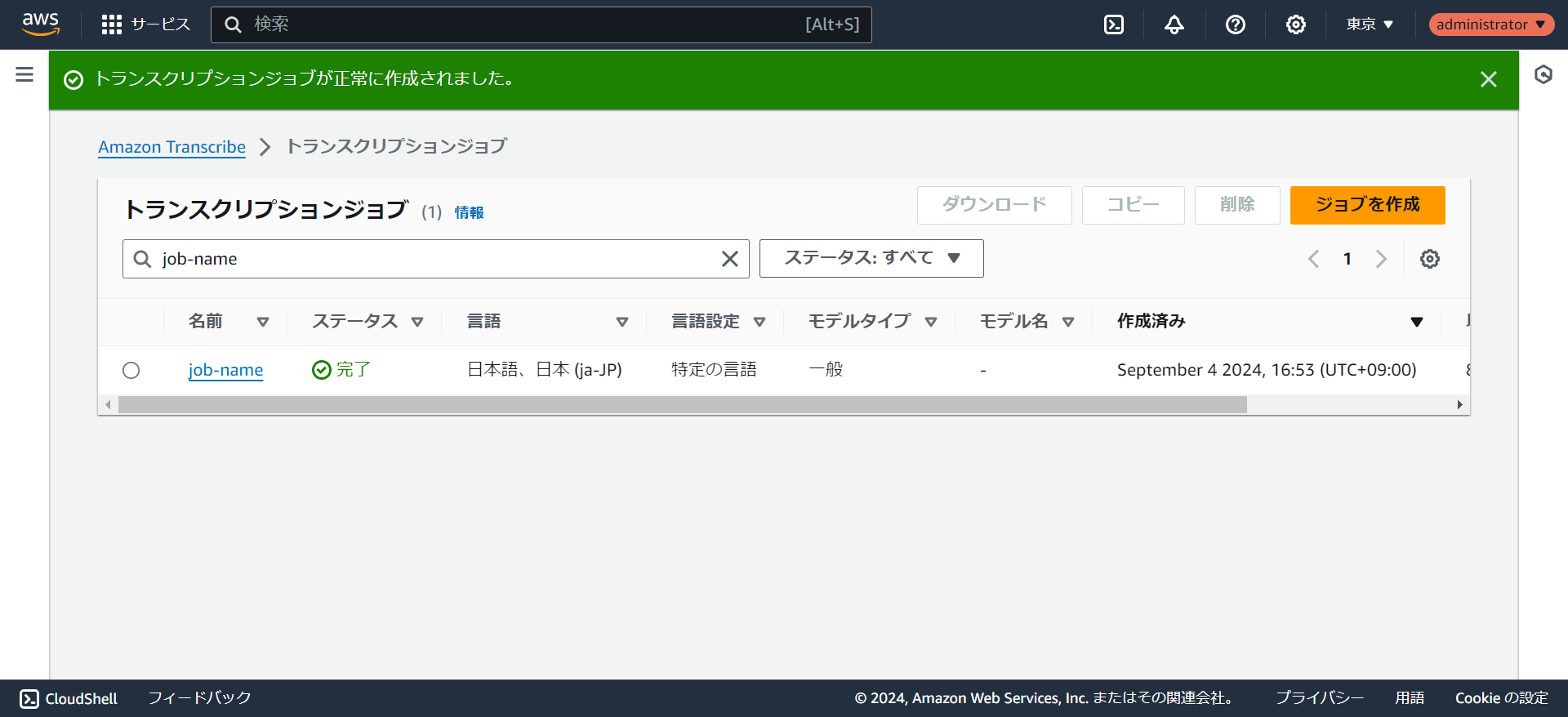
- 出力先をサービスマネージドS3に指定していればプレビューを確認することができます。結果をjsonでダウンロードすることもできます。
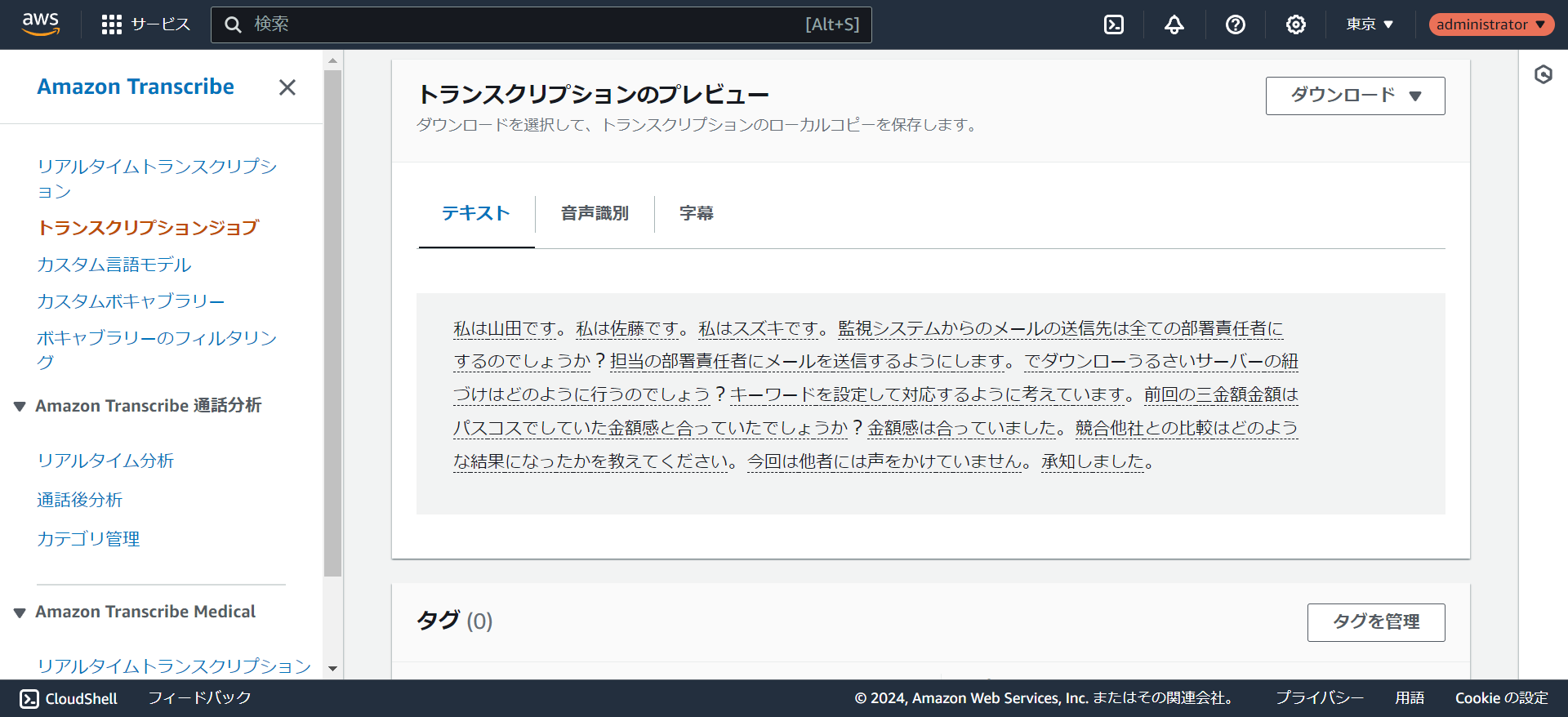
出力データについて
jsonの出力データは以下の形式になっています。1分くらいの音声データでも35000字のデータになるので構造を知らないと解析ができません。
- jobName: ジョブ名
- accountId: AWSのアカウント
- status:
COMPLETED - results
- transcripts
- transcript: 文字起こしの全文
- speaker_labels
- segments
- 発言の開始と終了時間。
[start_time, end_time, speaker_label]
- 発言の開始と終了時間。
- segments
- items
- トークンごとの開始と終了時間。
[id, type, alternatives, start_time, end_time, speaker_label]
- トークンごとの開始と終了時間。
- audio_segments
- 発言内容と開始と終了時間。
[id, transcript, start_time, end_time, speaker_label]
- 発言内容と開始と終了時間。
- transcripts
単純に文字起こしの全文が欲しい場合はtranscriptsのtranscriptを参照すれば良いです。
議事録のように誰が何を発言したかを取り出す場合はaudio_segmentsのspeaker_labelとtranscriptを参照します。
SDKから実行する方法
PythonのSDKで実行するには以下のようなコードで実行できます。
# クライアント生成
transcribe = boto3.client('transcribe')
# 文字起こしジョブ開始
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {'MediaFileUri': s3_uri},
MediaFormat = extension,
LanguageCode = 'ja-JP',
OutputBucketName = bucket_name,
OutputKey = output_key,
Settings = {
'ShowSpeakerLabels': True,
'MaxSpeakerLabels': 3
},
)まとめ
Amazon Transcribeでの文字起こしについて解説しました。SDKから容易に実行することができ、データをjson形式で取り出せるためシステムにも取り込みやすくなっています。これを機にAmazon Transcribeを使いこなしてみませんか?
この記事を書いた人


