
音声データをアップロードして議事録を作成するGPTsを構築しました。UIとしてChatGPTを活用し、バックエンドはAWSで構築しました。文字起こしにAmazon Transcribeを使用し、議事録への編集はAmazon Bedrockで生成AIにより行いました。
どんなGPTs?
画面を見てもらうのが早いと思います。
- 機能は受付と結果取得の2つ
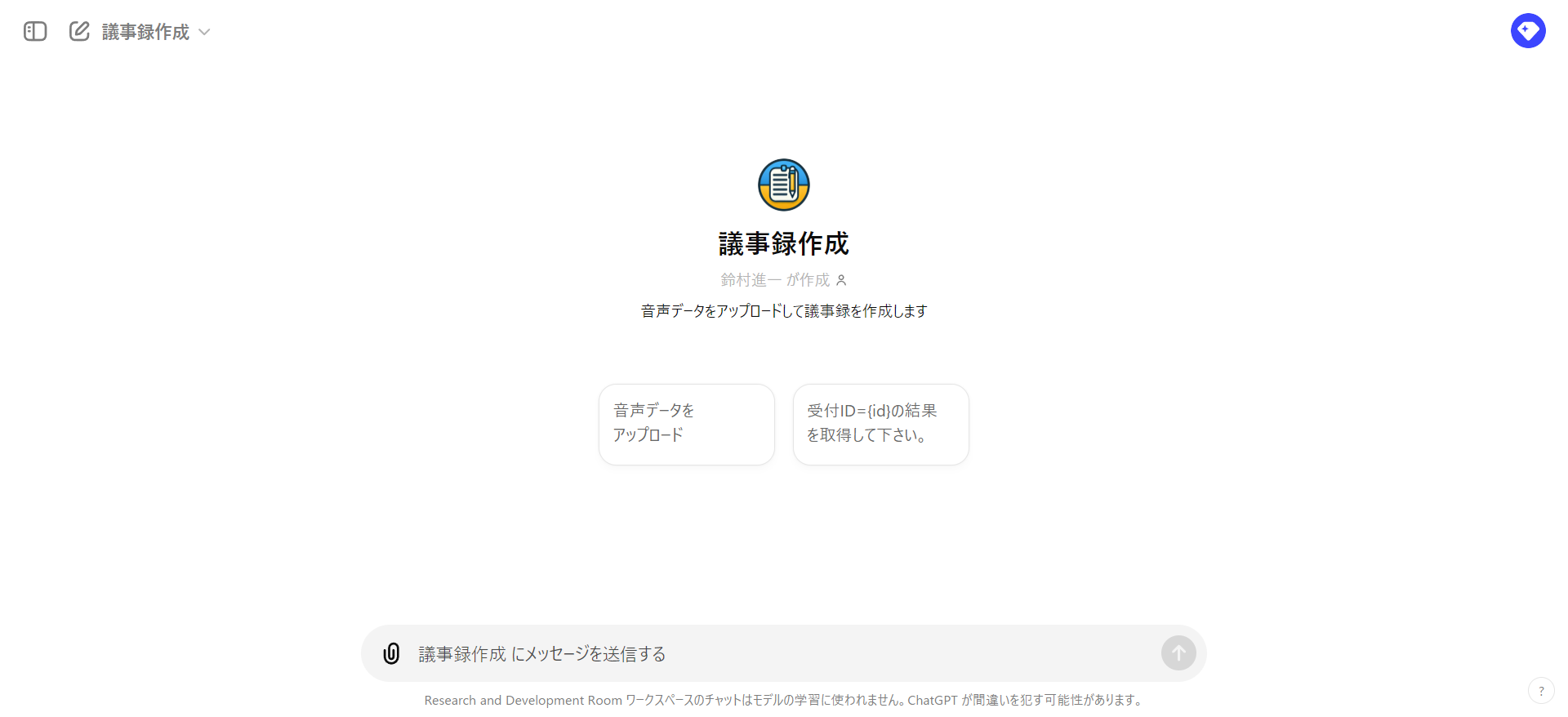
- 受付機能では音声データを受け取って、受付IDを返します。
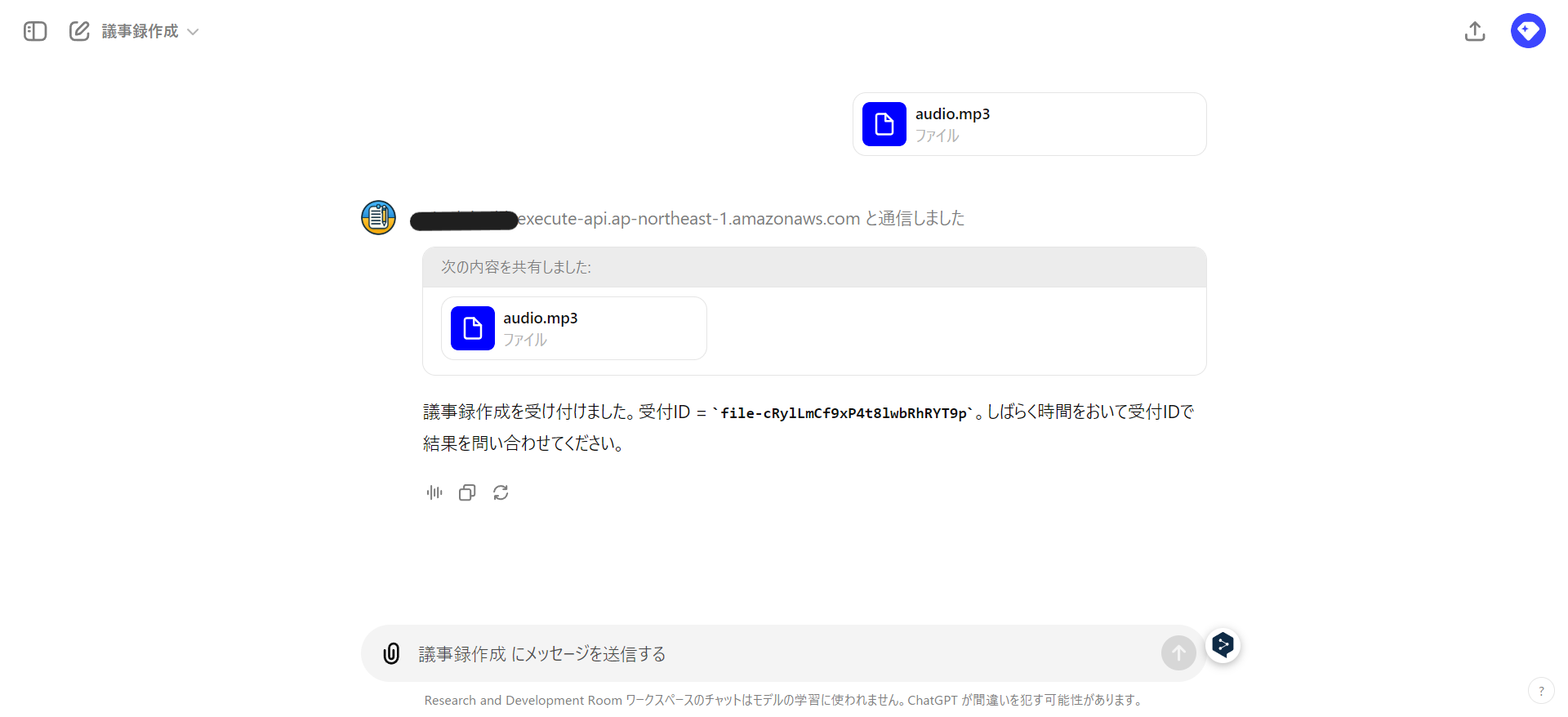
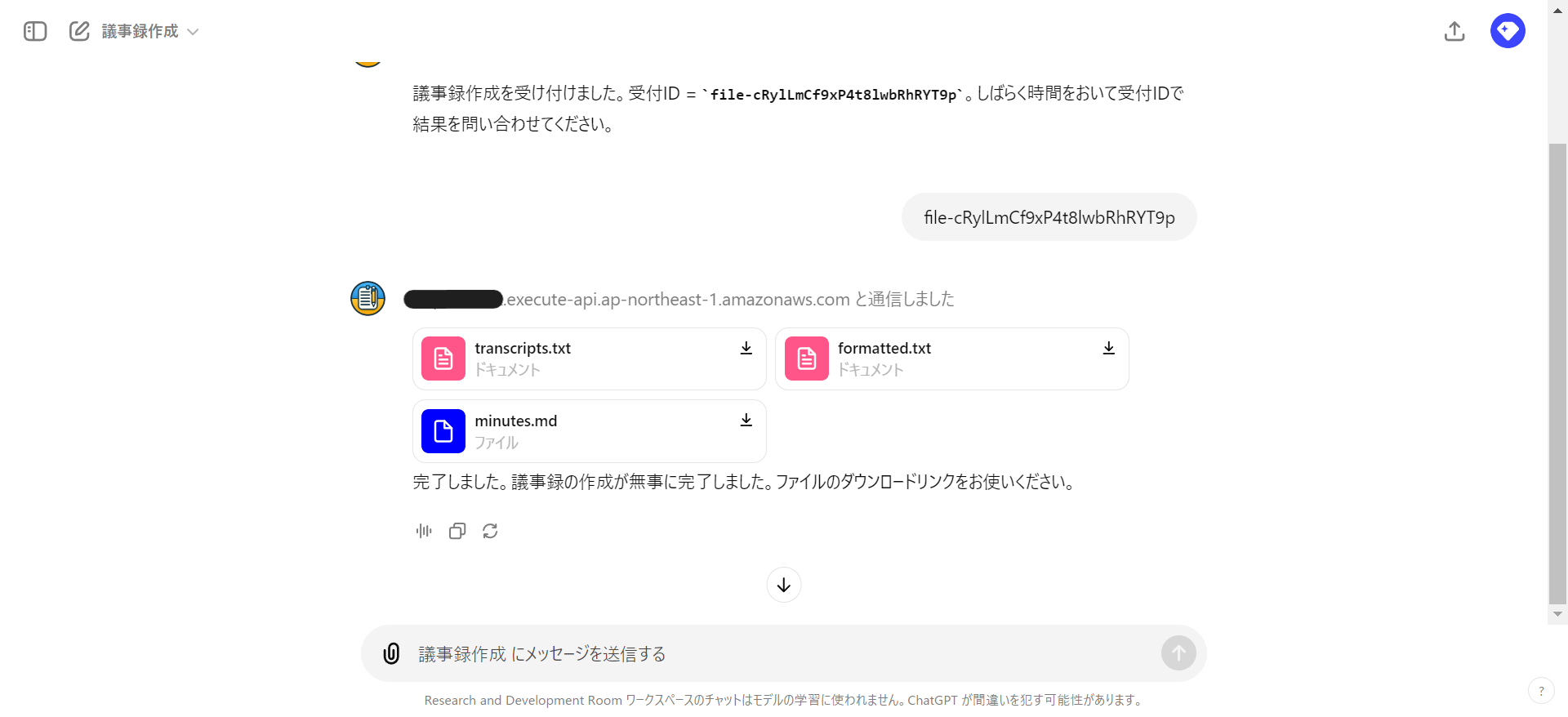
- 結果取得では受付IDを入力として作成したファイルをダウンロードできるようにします。
構成図
構成図は以下の通りです。
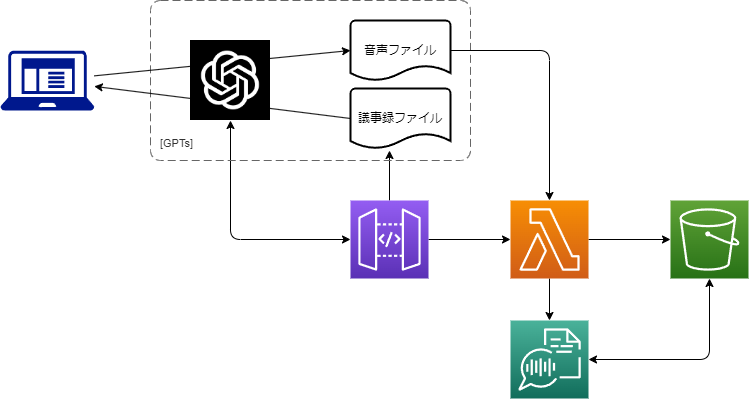
処理の流れ
- 受付APIでは以下の処理を実行します。
- パラメータのjsonデータをS3のunprocessed/プレフィックスにaccept.jsonを格納して受付IDを返します。
音声データのサイズが大きい場合、OpenAIからファイルを取得してS3に格納する間にGPTsのタイムアウト時間を過ぎてしまう事があるため、情報だけ受け付けます。
- パラメータのjsonデータをS3のunprocessed/プレフィックスにaccept.jsonを格納して受付IDを返します。
- unprocessed/プレフィックスにaccept.jsonが格納されたらS3イベント通知により文字起こし処理を起動します。この処理では以下を行います。
- パラメータのdownload_linkから音声データを取得しunprocessed/プレフィックスに保存します。
- 音声データを入力とするTranscribeジョブを起動します。
- Transcribeの処理結果はprocessed/プレフィックスに格納します。
- processed/プレフィックスにjsonが格納されたらS3イベント通知により議事録作成処理を起動します。この処理では以下を行います。
- Transcribe処理結果からaudio_segmentを読み取り話者と発言内容のみを抽出してtranscripts.txtを作成します。
- transcripts.txtの内容をBedrockにより整形します。フィラーを取り除いたり、誤字脱字を修正させて文字起こしの精度を上げます。この結果からformatted.txtを作成します。
- formatted.txtの内容からBedrockで議事録に編集してminutes.mdを作成します。
- transcripts.txt、formatted.txt、minutes.mdをcompleted/プレフィックスに格納します。
- 処理結果取得APIでは以下を行います。
- GPTsから受け取った受付IDの処理結果がcompleted/プレフィックスに格納されているか確認する。
- 格納されている場合: 3つのファイルを返す。
- 格納されていない場合: 処理中のメッセージを返す。
- GPTsから受け取った受付IDの処理結果がcompleted/プレフィックスに格納されているか確認する。
ポイント
何で文字起こしを行うか?
OpenAIのWhisperも検討しました。Whisperのオープンソースバージョンは無料で使えるのでコスト的には魅力でした。しかし、Whisperはファイルサイズが大きくLambdaで動かせない点と話者の識別ができない点がネックとなり諦めました。Whisperについては以下の記事を読んでみて下さい。
最終的には話者の認識ができるということでAmazon Transcribeを採用しました。Amazon Transcribeの動かし方については以下の記事を読んでみて下さい。
GPTsのアクションでファイルの送受信
GPTsのアクションでファイルを送受信する方法の情報が少なくて苦労しました。基本的には公式ドキュメントに書いてある手順通りで動くのですが、動かなかった時の原因調査が大変でした。同じような苦労をしなくて済むように興味のある方は以下の記事を読んでみて下さい。
Bedrockの生成結果が途中で切れてしまう問題
1時間の会議で約100Mの音声ファイルだと約10,000文字になります。これをBedrockで処理しようとする生成結果が途中で切れてしまい最後まで処理できませんでした。この問題を解決するためにBedrockの呼び出しを工夫しました。同様の問題で困っている方は以下の記事を読んでみて下さい。
まとめ
議事録作成GPTsの紹介でした。文字起こしだけでは精度が良くありませんが、生成AIで整形することでかなり精度が良くなります。ランニングコストとしては1時間の音声データで約250円です。
生成AIとAWSの学習にはちょうど良い教材だと思うので興味のある方はチャレンジしてみて下さい。業務で導入を検討したいという方はお問い合わせページからお問い合わせください。
この記事を書いた人


