
先日LangChainのバージョン1.0がリリースされました。今後、AIエージェントの構築の際に利用されることが多くなっていくのではないでしょうか。そこで、今回はLangChainの基本について解説したいと思います。
エージェント
create_agent
create_agent は LangChain 1.0 でエージェントを構築する標準的な方法です。
エージェントの挙動
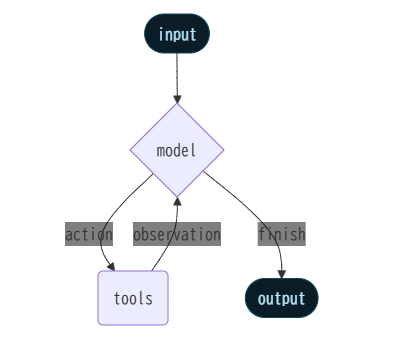
内部的には、create_agent は基本的なエージェントループに基づいて構築されています。モデルを呼び出し、実行するツールを選択させ、ツールをこれ以上呼び出さなくなった時点で終了します。
Message
メッセージの種類
- System message(システムメッセージ):
エージェントの基本的な役割を記述します。
エージェントの行動範囲や制約を明示的に指示します。 - Human message(ヒューマンメッセージ):
人間からの最初のリクエスト、またはフィードバックや介入の内容を含みます。 - AI message(AIメッセージ):
モデルが生成した出力を表します。
ここにはツール呼び出しや結果も含まれることがあります。
最終的に、エージェントの最後の AI メッセージが「最終結果」を提供します。 - Tool message(ツールメッセージ):
ツールの呼び出し結果を含むメッセージです。
LangChain におけるメッセージは、ノード間で直接送受信されるのではなく、
全ノードが共有する一時的なスクラッチパッド(メモリ領域) に保存されます。
ノードが実行されるたびに、その結果はメッセージとしてスクラッチパッドに記録されます。
したがって、モデルはツールの結果だけでなく、過去すべてのトランザクション履歴を参照できます。
これにより、モデルは元の質問、ツールの呼び出し、観察結果などを参照し、
それらを踏まえた上で最終的な推論結果を生成できます。
出力形式
エージェントを実行した結果は以下のようになっています。 HumanMessage、AIMessage、ToolMessage、AIMessageの順でやり取りされています。
{'messages': [
HumanMessage(content='Please write me a poem', additional_kwargs={}, response_metadata={}, ~中略~),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 1066, ~中略~}, tool_calls=[{'name': 'check_haiku_lines', ~中略~ 'type': 'tool_call'}], usage_metadata={'input_tokens': 170~中略~}}),
ToolMessage(content='Correct, this haiku has 3 lines.', name='check_haiku_lines', ~中略~),
AIMessage(content='Stadium lights wake\nCrowds hum like tides before play\nFirst whistle splits dusk', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 20, ~中略~}}, 'model_provider': 'openai', 'model_name': 'gpt-5-2025-08-07', ~中略~}, usage_metadata={'input_tokens': 230, ~中略~}})]}
AIMessageには usage_metadata と response_metadata が含まれており、トークン数やモデルなどの情報を得ることができます。
Streaming
モード
LangChain エージェントのストリーミングモードには、以下の5種類があります:
- Messages モード:モデルがトークンを生成するたびに、1トークンずつ逐次ストリームします。
- Values モード:モデルの各ステップ(推論、ツール呼び出しなど)が完了するたびに、結果を返すモードです。
- Updates モード:各エージェントステップの後に状態の更新を取得するモードです。
- Customモード:ノード内部からユーザー定義データを送信するモードです。
- Debugモード:グラフの実行中、可能な限り多くの情報をストリーム処理するモードです。
複数のソースから同時にストリームすることも可能です。
Toolからストリーミング
LangGraphノードまたはツール内部からカスタムユーザー定義データを送信するには、次の手順に従ってください:
- get_stream_writerを使用してストリームライターにアクセスし、カスタムデータを送信します。
- ストリーム内でカスタムデータを取得するには、.stream() または .astream() を呼び出す際に stream_mode=”custom” を設定します。
サンプルコード
以下のコードでは get_weatherツール から処理の途中経過とモデルの各ステップの結果をストリーミングします。
def get_weather(city: str) -> str:
"""Get weather for a given city."""
writer = get_stream_writer()
writer(f"Looking up data for city: {city}")
writer(f"Acquired data for city: {city}")
return f"It's always sunny in {city}!"
agent = create_agent(
model="openai:gpt-5-mini",
tools=[get_weather],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
stream_mode=["values", "custom"],
):
print(chunk)Tool
ツールは ReAct エージェントにおける「行動(Act)」の部分 を担います。ツールの実行結果は「観察結果(observation)」として扱われます。ツールは自分で作成することも、既存のツールライブラリを利用することも可能です。
各ツールには、明確な名前、説明、引数名、および引数の説明が必要です。これらは単なるメタデータではなく、モデルがツールをいつ、どのように使用するかを判断する指針となります。引数の構造(型や名前)は関数シグネチャから自動的に取得されます。
ツール本体の関数は、LangGraph の ツールノード(Tool Node) で実行されます。
@toolデコレータ
ツールの説明をより具体的に記述するためにLangChain では、@toolデコレータ が準備されています。以下のように parse_docstring=True を指定することでdocstringを解析し、ツールのスキーマにパラメータの説明を反映します。
サンプルコード
以下のコードではツールの名前を calculator とし、2つの実数に対して基本的な算術を行うツールであることを説明しています。parse_docstring=True を指定することでdocstringの内容を解析しツールのパラメータに反映します。
@tool(
"calculator",
parse_docstring=True,
description=(
"2つの実数に対して基本的な算術演算を実行します。"
"整数であっても、任意の数に対する演算が必要な場合はいつでもこれを使用してください。"
),)
def real_number_calculator(
a: float, b: float, operation: Literal["add", "subtract", "multiply", "divide"])
-> float:
"""2つの実数に対して基本的な算術演算を実行します。
Args:
a (float): 最初の数。
b (float): 2番目の数。
operation (Literal["add", "subtract", "multiply", "divide"]):
実行する算術演算。
- `"add"`: `a` と `b` の和を返します。
- `"subtract"`: `a - b` の結果を返します。
- `"multiply"`: `a` と `b` の積を返します。
- `"divide"`: `a / b` の結果を返します。`b` が 0 の場合、エラーを発生させます。
Returns:
float: 指定された演算の数値結果。
Raises:
ValueError: 無効な演算が指定された場合、または 0 による除算が試行された場合。
"""MCP
基本的な動作は、LangChain における標準的なツールフローと似ています。違いは、ツールの説明(description)が MCP サーバー経由のシグナリングによって取得される 点です。また、ツールの実行はツールノードではなく、MCP サーバー上で実行されるという点も異なります。
MCPサーバーに接続するにはlangchain_mcp_adapters.client から MultiServerMCPClient をインポートします。
サンプルコード
以下のコードでは @theo.foobar/mcp-time MCPクライアントを定義し、mcp_tools = await mcp_client.get_tools() で利用可能なツールの情報を取得します。取得したツール情報を tools=mcp_tools でエージェントに設定することでMCPサーバーの呼び出しを可能にしています。
MCPサーバーの呼び出しは非同期となるため、.ainvoke() で呼び出します。
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
import nest_asyncio
nest_asyncio.apply()
mcp_client = MultiServerMCPClient(
{
"time": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@theo.foobar/mcp-time"],
}
},
)
mcp_tools = await mcp_client.get_tools()
print(f"Loaded {len(mcp_tools)} MCP tools: {[t.name for t in mcp_tools]}")
agent_with_mcp = create_agent(
model="openai:gpt-5",
tools=mcp_tools,
system_prompt="You are a helpful assistant",
)
result = await agent_with_mcp.ainvoke(
{"messages": [{"role": "user", "content": "What's the time in SF right now?"}]}
)
for msg in result["messages"]:
msg.pretty_print()メモリ
エージェントは過去のリクエストを記憶していません。この問題を解決するには、メモリ(Memory)を追加します。LangChain のエージェントには、LangGraph を基盤としたメモリ機能が組み込まれています。メモリを追加することで、メッセージや状態をエージェントの呼び出し間で永続化できます。
ランタイムとコンテキスト
LangChain の create_agent() は、内部的に LangGraph のランタイム 上で動作します。LangGraph は runtime オブジェクトを公開しており、そこには次のような情報が含まれています:
- context:ユーザーID、データベース接続など、エージェントに注入する静的な情報。
- store:長期メモリとして使える基本的なストアインスタンス。
- stream_writer:ストリーミングデータを出力するための仕組み
ツールやカスタムミドルウェア内からも、この runtime にアクセスできます。これにより、静的な情報をツールやプロンプトに簡単に引き渡せます。
メモリ
メモリは、特に長時間対話を行うエージェントにおいて極めて重要です。途中で中断や一時停止があっても、以前の会話状態を保持することで、より自然で生産的な対話を続けられます。
LangChain では、メモリを大きく分けて2種類扱います:
- 短期メモリ(Short-term memory) – 会話間での状態保持(チェックポイント)
- 長期メモリ(Long-term memory) – 永続的な保存(データベースやファイルベース)
短期メモリを追加するには langgraph.checkpoint.memory から InMemorySaver を import します。さらに、エージェントを呼び出す際、config 引数に thread_id を指定します。これにより、会話スレッドごとに状態を追跡できます。
サンプルコード
エージェント構築時に checkpointer=InMemorySaver() 短期メモリを有効にし、エージェント実行時に {“configurable”: {“thread_id”: “1”}} でスレッドIDに”1”を指定しています。以降で再度スレッドID=”1″でエージェントを実行することで前回の内容を引き継げます。
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
from langchain_core.messages import SystemMessage
agent = create_agent(
model="openai:gpt-5",
tools=[execute_sql],
system_prompt=SYSTEM_PROMPT,
context_schema=RuntimeContext,
checkpointer=InMemorySaver(),
)
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
{"configurable": {"thread_id": "1"}},
context=RuntimeContext(db=db),
stream_mode="values",
):
step["messages"][-1].pretty_print()Structured Output
LangChain の組み込みエージェントが持つ強力な機能のひとつが、構造化出力(Structured Output)を生成できる点です。エージェントが既存のシステムと連携して動作する場合、定義済みのフォーマットでデータを出力できることは非常に重要です。
構造化出力(Structured Output)を行うには 出力フォーマット(response_format) にデータ型 を指定します。これにより、エージェントが返すデータは必ずこの構造に従います。
Python 版では、構造化出力として以下のデータ型をサポートしています:
- Pydantic BaseModel
- TypedDict
- Dataclass
- Raw JSON Schema(生のJSONスキーマ)
サンプルコード
以下のコードでは TypedDict 型の ContactInfo を response_format に指定することで、エージェントの実行結果を ContactInfo で出力します。
from typing_extensions import TypedDict
from langchain.agents import create_agent
class ContactInfo(TypedDict):
name: str
email: str
phone: str
agent = create_agent(model="openai:gpt-5-mini", response_format=ContactInfo)Dynamic Prompt
ミドルウェア(Middleware)による拡張
ミドルウェアを使うと、ReAct ループ内の重要なタイミングで、エージェントに固有のコードを挿入できます。
LangChain では主に2種類のフックが提供されています:
- ノードフック(Node Hooks) – 特定のノード実行時に処理を追加できます。
- インターセプターフック(Interceptor Hooks) – ノード全体を包み込むように動作します。
これらのフックの一般的な用途として、以下のようなものがあります:
- 要約(Summarization)
- ガードレール(Guardrails)
- 動的プロンプト生成(Dynamic Prompts)
- ツールのリトライ(Tool Retries)
動的プロンプトとは
エージェントが扱うタスクの範囲や期間が広がるにつれ、プロンプトも複雑化し、フェーズやステップ、条件分岐を含むようになります。このような場合、状況に応じてプロンプトを切り替える仕組みが必要になります。それが「動的プロンプト(Dynamic Prompting)」です。動的プロンプトは、ランタイムコンテキスト(Runtime Context) やエージェントの現在の状態に応じて、リアルタイムに内容を選択できます。
サンプルコード
以下のコードでは Runtime Context の is_employee の値により、システムプロンプトの {table_limits} 部分を動的に置き換えています。
from langchain.agents.middleware.types import ModelRequest, dynamic_prompt
from langchain.agents import create_agent
SYSTEM_PROMPT_TEMPLATE = """You are a careful SQLite analyst.
Rules:
- Think step-by-step.
- When you need data, call the tool `execute_sql` with ONE SELECT query.
- Read-only only; no INSERT/UPDATE/DELETE/ALTER/DROP/CREATE/REPLACE/TRUNCATE.
- Limit to 5 rows unless the user explicitly asks otherwise.
{table_limits}
- If the tool returns 'Error:', revise the SQL and try again.
- Prefer explicit column lists; avoid SELECT *.
"""
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
if not request.runtime.context.is_employee:
table_limits = "- Limit access to these tables: Album, Artist, Genre, Playlist, PlaylistTrack, Track."
else:
table_limits = ""
return SYSTEM_PROMPT_TEMPLATE.format(table_limits=table_limits)
agent = create_agent(
model="openai:gpt-5",
tools=[execute_sql],
middleware=[dynamic_system_prompt],
context_schema=RuntimeContext,
)Human In The Loop
多くのケースで、エージェントは人間の介入(Human in the Loop、HITL)を必要とします。これは、エージェントが自律的に判断できない状況や、人間による最終確認が必要なケースで特に重要です。
エージェントを作成する際に、Human in the Loop ミドルウェアを追加し、どのツールで人間の承認を求めるかを指定します。
サンプルコード
以下のコードではツール毎に承認の範囲を指定しています。
- write_fileツール :approve、reject、edit の全てを選択可能
- execute_sqlツール :approve、rejectのみ選択可能。editは選択不可。
- read_dataツール :人間の介入なく実行可能
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4o",
tools=[write_file_tool, execute_sql_tool, read_data_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"write_file": True,
"execute_sql": {"allowed_decisions": ["approve", "reject"]},
"read_data": False,
},
description_prefix="Tool execution pending approval",
),
],
checkpointer=InMemorySaver(),
)まとめ
LangChainの基本を解説しました。これらのポイントを理解するだけでも簡単なエージェントを構築できます。何事も基本が大切です。しっかり理解してエージェントの学習を進めましょう。
この記事を書いた人


