
2024/10/1にOpenAIからModel Distillation in the APIが発表になりました。敷居の高かったFine-tuningを手軽に行えるようにする仕組みです。今まで行えなかったEvaluation(評価)まで行えるようになっています。
Distillationとは?
データ作成、Fine-tuning、評価の一連の流れをOpenAIのプラットフォーム上で行えるようにする仕組みです。GPT-4oのような大きなモデルでデータを作成し、GPT-4o-miniのような小さなモデルをチューニングすることで効率的にチューニング済みのモデルを作成できます。3つの機能に分かれています。
- Stored Completions: Chat Completions APIの結果を保管できるようになりました。保管したデータは学習データや評価データとして活用できます。
- Fine-tuning: Stored Completionsで保管したデータを使ってFine-tuningを行います。
- Evals: Stored Completionsで保管したデータを使ってチューニング済みのモデルの評価を行います。
Stored Completions
OpenAIのChat Completions API呼び出しの際にパラメータにstore=TrueをついかすることでAPI呼び出しの結果をOpenAIのプラットフォーム上に保管することができるようになりました。保管するデータはmetadataで区別することができます。
以下のコードではft-modelとcategoryというメタデータでモデルと用途を区別できるようにしています。
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "学習データに関するエキスパートです。学習データに関する質問に回答します。"},
{"role": "user", "content": "学習データ用の質問"}
],
store=True,
metadata={"ft-model": "model-name", "category": "study",}
)
print(response.choices[0].message.content)Chat Completions APIを実行するとOpenaAIのChat Completionsに結果が保管されています。
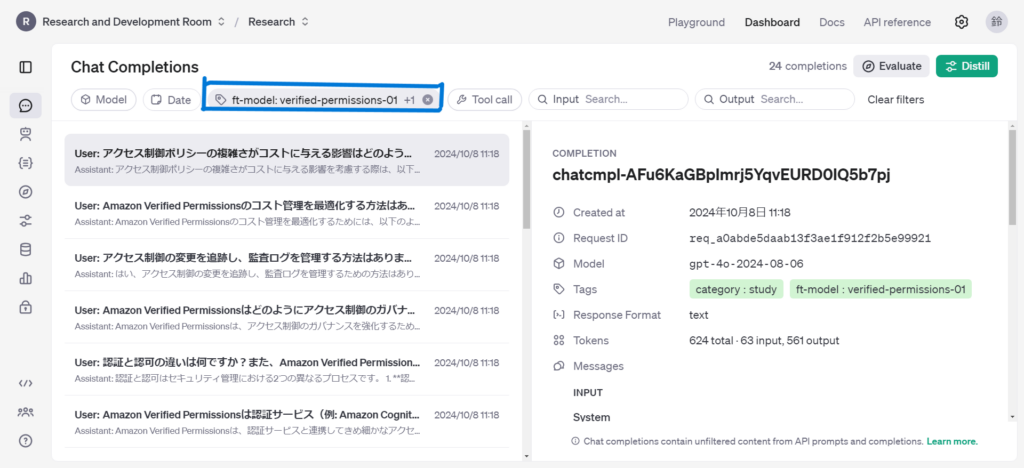
Fine-tuning
Stored Completionsに保管されたデータからFine-tuningを行うにはDistillボタンをクリックします。使用するデータの選択はフィルタリングで行います。metadataを適切に設定しておかないとデータが混ざってしまうので注意しましょう。
Distillボタンをクリックすると以下のようにFine-tuningの設定ダイアログが表示されます。
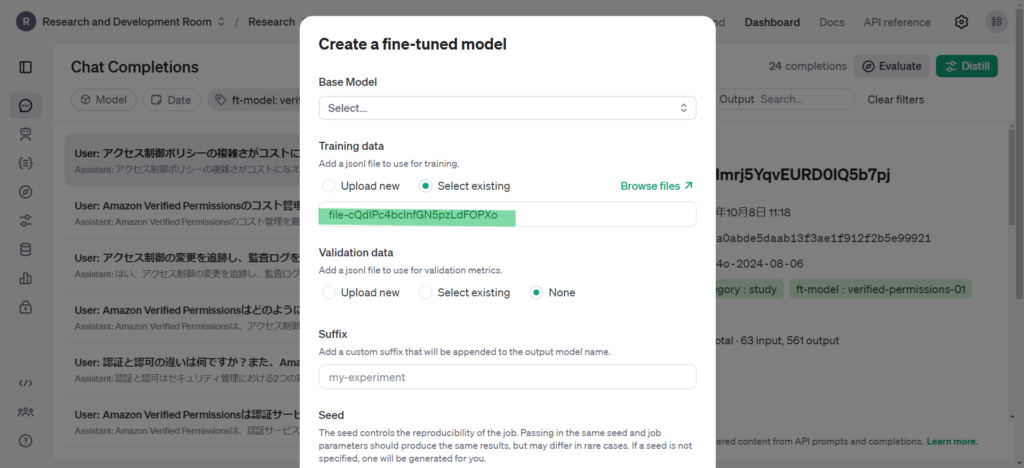
Training dataにはStored Completionsでフィルタリングしていたデータからjsonlファイルが作成され設定されます。以下を設定してcreateボタンをクリックするとFine-tuningが開始されます。
- Base Model:学習させる元のモデルを選択します
- Validation data:Fine-tuningの検証データを設定します
- Suffix:チューニング済みモデルを識別するための接尾辞を設定します。省略してしまうとモデル名がランダムの文字列となってしまうので分かりやすい接尾辞を設定しましょう。
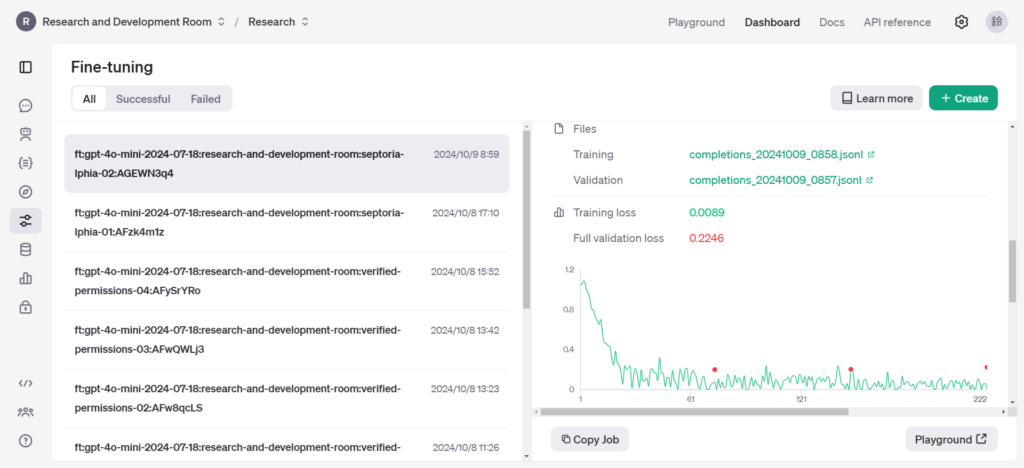
Fine-tuningの画面で結果を確認することができます。
Evals
Fine-tuningと同様にStored Completionsから評価データをフィルタリングした状態でEevaluateボタンをクリックするとEvaluationsの設定画面に遷移します。Test dataにはStored Completionsでフィルタリングしていたデータからjsonlファイルが作成され設定されます。
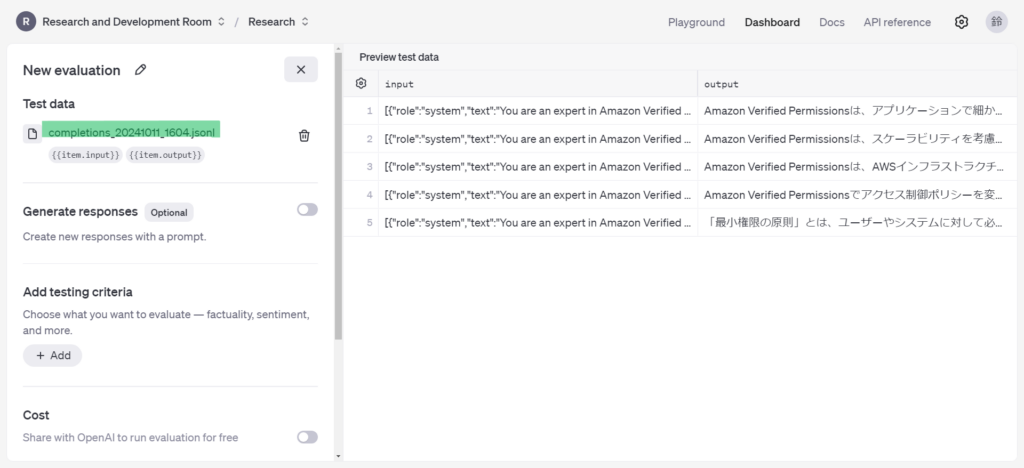
追加で以下を設定して、RUNボタンをクリックすると評価が実行されます。
- Generate responses:チューニング済みモデルのレスポンスを評価に使用する場合に設定が必要です。
- Prompt:評価に使用するプロンプトを入力します。
{{item.input}}を選択することで評価データと同じ質問を使用することができます。 - Generate with:レスポンスを生成するモデルを選択します。
- Prompt:評価に使用するプロンプトを入力します。
- Add testing criteria:評価方法を選択します。複数の評価方法を設定することも可能です。
- Factuality:事実性のチェック。5段階で評価。
- Semantic similarity:意味的類似性のチェック。5段階で評価。
- Sentiment:センチメント分析。3段階で評価。
- String check:特定の文字が含まれるかのチェック。passかfailの2択。
- Valid JSON or XML:JSONやXMLとして正しいかのチェック。passかfailの2択。
- Matches schema:回答がJSONスキーマに準拠しているかのチェック。passかfailの2択。
- Criteria match:回答が基準を満たしているかのチェック。passかfailの2択。
- Text quality:文章の品質をチェック。5段階評価。
- Custom prompt:任意のプロントで評価する。評価基準も好きに決められる。
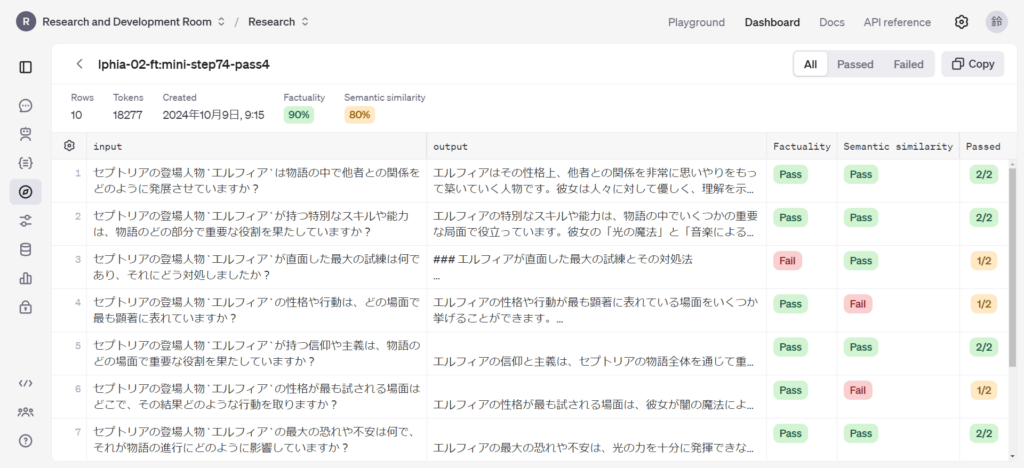
以下が評価結果です。それぞれの評価方法についての評価結果を確認することができます。歯車ボタンで表示する項目を変更することでモデルからの出力結果を確認することもできます。
まとめ
OpenAIのDistillationについて解説しました。今までは学習データのjsonlを自分で作成したり、評価するためにevalsを実行できる環境を整えて実行する必要があり、手間がかかっていました。Distillationが使えるようになったことで今までよりも手軽にFine-tuningを行えるようになりました。学習データも生成AIに作らせることができるので精度が上がり、工数を減らせます。これを機にFine-tuningに挑戦してみてはいかがでしょうか?
この記事を書いた人


